歡迎回到我們的30天人臉技術探索之旅!今天我們將介紹 Head pose 的知名架構,以助我們之後實做方便!今天會介紹兩個非常經典的結構——HyperFace和HopeNet。這兩個模型在多目標檢測和姿態估計方面都取得了重要的成就。
還記得我們之前介紹過得 MTCNN 嗎?在MTCNN 的架構中,模型除了會去預測人臉框的座標也同時會去多預測人臉關鍵點的位置,這樣多任務是接在同一個 backbone 的架構就是 Mutitask 架構!
那除了多人臉關鍵點我們是不是可以在加入其他 task 進到我們模型結構,例如多讓模型去預測 Headpose 等等?答案是可以的,我們接下來就要跟他介紹一下非常經典的模型 -- HyperFaceHyperFace 是一種深度學習模型,主要用於多目標檢測。其核心思想是同時檢測並提取多個目標的特徵,包括人臉、眼睛、嘴巴等。如下圖: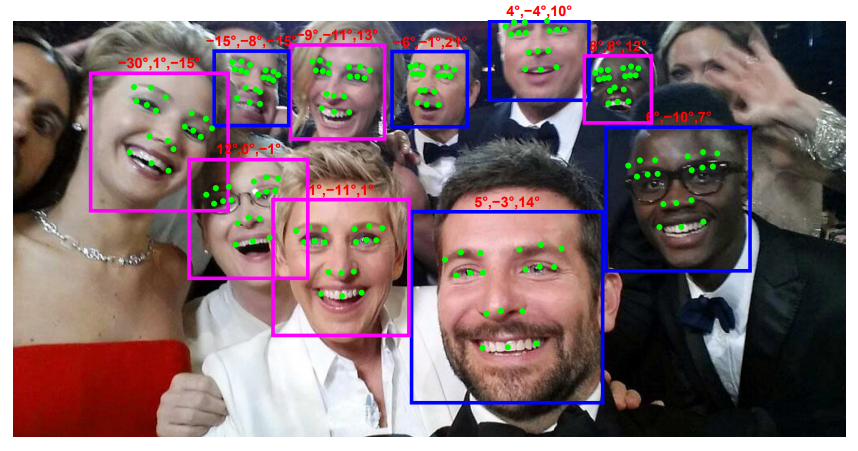
以上皆是 HyperFace model 去預測出來的數值,你可以看到除了人臉框以及綠色的人臉關鍵點,HyperFace也預測出了紅色的Head pose 等等
那以下是 HyperFace 的主要我們需要注意的技術細節:
1.多分支架構: HyperFace 使用了一種多分支(multi-branch)的網絡結構,如下圖。每個分支專注於檢測和提取一個目標的相關特徵。這種結構使得模型能夠同時進行多個任務,並在單一模型中實現多目標檢測。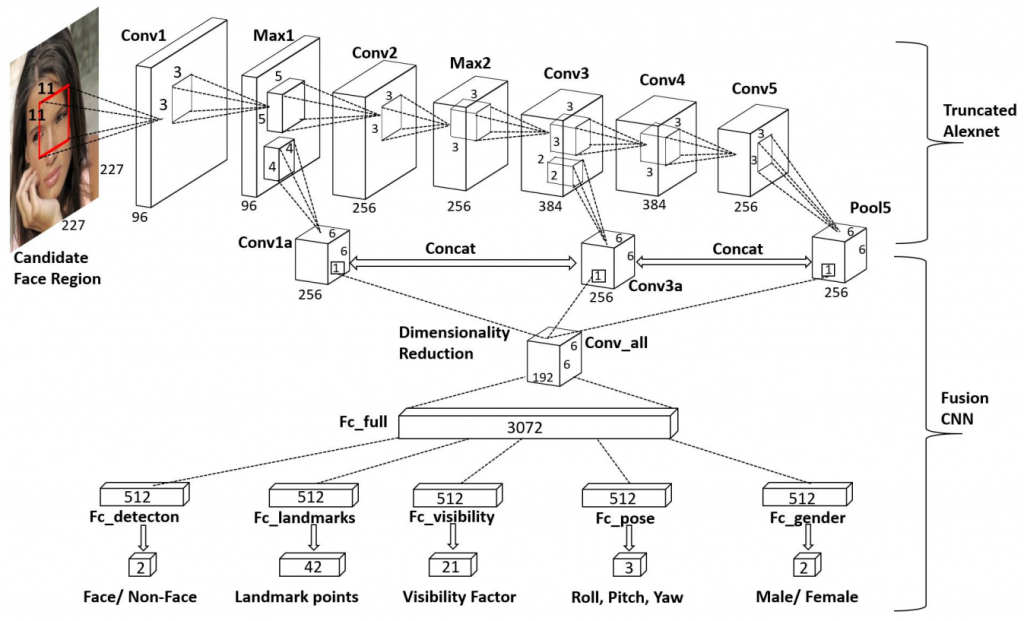
2.共享特徵提取器: HyperFace 中的各個分支共享一個特徵提取器。這意味著在提取圖像特徵時,各個目標之間可以共享信息。這樣的共享機制有助於提高模型的效率和整體性能。
3.結合檢測和特徵提取: 作者認為卷積神經網路(CNN)的層數較淺的卷積層包含更多細節和局部信息,因此更適合用於關鍵點定位和姿態估計。相比之下,層數較深的卷積層則包含更多整體信息,可用於處理更複雜的任務,例如人臉檢測和性別預測。本文的獨特之處在於充分利用了中間層特徵,並採用了多任務學習的策略,使網路在不同層次上更全面地學到了有關數據的信息。因此設計上 HyperFace 不僅僅是一個檢測器,還是一個特徵提取器。每個分支不僅負責目標的檢測,還同時提取出該目標的高層次特徵。這種一體化的設計使得 HyperFace 在多目標檢測任務中表現出色。
4.應用範疇: HyperFace 主要應用於需要同時檢測多個目標的場景,例如監控系統、智能攝像頭等。其高效的多目標處理能力使其在實時應用中大放異彩。
那 HyperFace 有沒有缺點呢?答案是有的,主要是慢,有以下原因:a.模型結構複雜:大家可以看看上圖的網路結構 trucate alexnet 的部份,作者想要使用每一層的資訊,因此有逐層結合,這樣會大幅降低速度b.非常複雜的後處理法:HyperFace 中一共有两種后處理方法:iterative region proposals(RCNN系列的selective search,整體最耗時的地方) and landmarks-based non-maximum suppression。 iterative region proposals 若大家有興趣可以去看看 RCNN 的方法以及如何改善,這裡直接講結論:
HyperFace 在 TITANX 上一張圖要跑 3 sec,其中 2 sec 是跑這個 iterative region proposals!
那 HyperFace 我們要來改善的話,其實實務上可以用簡單的 resnet 或者 mobilenet 來取代 a 提到的問題,而 可以參考 Faster-RCNN 的 RPN 來解決 b.
HopeNet 是一種專注於頭部姿態估計的深度學習模型。頭部姿態估計通常包括估計頭部的旋轉角度,例如偏航、仰角和滾動。以下是 HopeNet 的主要技術細節:
1.全局-局部架構: HopeNet 使用一種全局-局部的架構。它同時關注全局特徵,如整個頭部的形狀,以及局部特徵,如眼睛、鼻子等部位的細節。這種架構有助於綜合考慮整個頭部的信息。
2.回歸角度: HopeNet 的主要目標是通過深度學習直接回歸頭部的旋轉角度。這意味著模型學習從輸入圖像中預測頭部的傾斜、仰角和旋轉角度,而無需過多的後處理。
3.結合分類以及回歸: HopeNet在設計上是先預測出角度介於那一個區間,然後在 fine-grained 的預測出做後的數字,如下圖: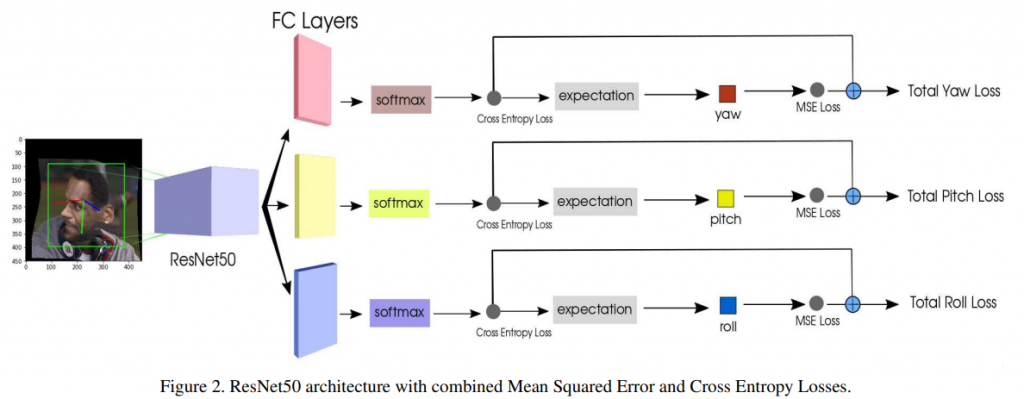
HopeNet 一共先把角度分成了 30 幾個 class 讓模型去預測,然後細分最後的數字!這樣的設計可以有效讓 model 學習 representation
4.強大的泛化能力: HopeNet 在頭部姿態估計方面表現出色,具有較強的泛化能力。即使在不同光線、不同場景下,HopeNet 仍能穩定且精確地估計頭部的姿態,這使其適用於各種應用場景。並且在訓練上採取了擁有大的 head pose的照片的 dataset -- 300w-LP 去做訓練所以在面對大角度的照片時一樣可預測得很不錯。效果如下圖:
5.實時應用: HopeNet 因為模型是設計簡單的端到端形式以及不需要 landmark 預測等原因的快速推斷速度使其適用於實時應用,如虛擬現實、遠程會議等場景,這些場景對頭部姿態估計的實時性要求較高。
我們今天介紹了 HyperFace 以及 HopeNet 這兩個在 Head pose 領域非常著名的模型!HyperFace 和 HopeNet 分別代表了多目標檢測和頭部姿態估計方面的先進技術。它們的出現使得人臉技術在複雜場景中更加強大和靈活。這兩種模型的結合應用有望為各種實時檢測和分析提供更全面、更準確的解決方案。
我們將於明晚帶著大家實做自己的 HopeNet,歡迎大家明晚繼續回來!
1.Ranjan, R., Castillo, C. D., Chellappa, R. (2016). HyperFace: A Deep Multi-Task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence.
2.Ruiz, Nataniel, Eunji Chong, and James M. Rehg. "Fine-grained head pose estimation without keypoints." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018.


 iThome鐵人賽
iThome鐵人賽